Is C# pass by reference or pass by value?
One of the first things we learn with our first programming language is the difference between passing by value and passing by reference. We learn that, in .NET, structs are passed “by value” and classes are passed “by reference”. Ask anyone who is a reasonably experienced C# programmer and they will probably tell you that “Structs are passed by value, classes are passed by reference”, as if repeating a mantra.
We say this because when we pass a struct to a method and we modify the structure in that method we are modifying a copy, not the original. With classes however the reverse is true; if we modify it we are modifying the original because we are modifying it through a reference, and both variables point to the same object on the heap. For example:
var a = new Person { Name = "Alex" };
var b = a;
b.Name = "Sam";
Console.WriteLine(a.Name); // Prints "Sam"This is all true and well-understood, but in actual fact this is not what “passing by reference” means. It may sound like splitting hairs, but this is “passing a reference by value“; the confusion arises from the fact that the values you are passing are references.
The reason this is confusing is because high-level OO languages such as C# deliberately hide from you the existence of references. You, as the programmer, never need to explicitly dereference a pointer and the syntaxes at method calls and variable assignments do not give any indication that the value is a reference.
Funnily enough C# does actually allow passing by reference by use of the ref keyword, but most C# programmers (those that don’t work in performance-critical domains) won’t be very familiar with it.
Allow me to explain with a simple example; let’s ignore the two cases of structs and classes for a moment and imagine we’re working in a language that’s just like C# except that it only has structs (value types); there is no object heap at all. This will allow us to look at variable passing in isolation. Now, imagine we have written two methods in our language, F and G, and we want to call G from F, passing a value as we do so:
void F()
{
int x = 5;
G(x);
}
void G(int y)
{
// ...
}The stack for these two methods might look something like this:
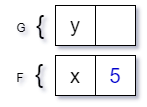
In order to pass the value 5 between our two methods F and G we need to somehow transfer this value to the new stack frame. The two choices we have are to either (a) copy the value from the old stack frame into a new stack frame:
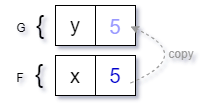
or (b) create a reference from the variable in the new stack frame to variable in the old stack frame:
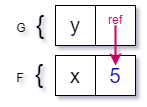
Scenario (a) is what we call pass-by-value (the value is copied into the new stack frame) and scenario (b) is pass-by-reference, that is passing a value into a method call creates a reference to the original value instead of performing a copy.
Note: I am talking exclusively about passing arguments to methods in my examples, but the same logic applies to simple variable assignment as well.
Let’s pause for a moment and take in the fact that we’ve introduced the concepts of pass-by-value and pass-by-reference even though we’re talking about a play language that has no reference types. This is an important realisation: that passing by reference is a completely distinct concept from that of a reference type.
Now that we’ve reached this stage of enlightenment we can proceed with the introduction of reference types into our theoretical language. Let’s see how the presence of an object heap changes our diagram:

You can see that the variable x, although it still lives on the stack, is now just reference to an object on the heap. What happens when we pass this variable to the call of the second function G?

The reference is copied! This is pass-by-value. The confusion is because the value that we’re passing is a reference, it’s understandable that people think this is pass-by-reference. “So”, you may ask, “What is passing a reference type by reference?”. Let’s take the exact same process we did for value types and apply it to the reference:

It’s a double reference, that is: a reference to a reference to an object. Again, C# completely hides this from you by automatically dereferencing when you make use of the variable, such as in this example:
public void M(ref Person p)
{
Console.WriteLine(p.Name); // <-- `p` is automatically dereferenced here
}Now that we’ve been through all the scenarios, let’s consolidate our diagrams into a matrix so we can see the four different scenarios laid out:

As far as I can tell the confusion has arisen because of a lack of common understanding of what pass-by-reference means. This is something that even seasoned developers can’t quite agree on. The situation is not helped by the fact that Microsoft’s own documentation seems to use the term pass by reference in place of “passing a reference”.
Whenever someone asks me whether C# is pass-by-reference or pass-by-value I tailor my answer to the person asking. To a novice I will say “pass-by-reference” because they’re unlikely to understand the necessary nuance of the real answer.
If an experienced but non-C# dev asks me I normally hedge my bets by saying “C# is pass-reference-by-value“. That normally clears things up by making them ask for more info!
The performance characteristics of immutability
If someone asks “What’s the difference between functional and imperative programming?” it’s tempting to reach for the technical definition which is that “a functional program is composed of functions whereas an object-oriented program is composed of classes”. However, a more fundamental difference between functional languages and their cousins in the object-oriented and procedural spaces is the extensive use of immutability.
The reason I consider this to be a more fundamental difference is because object-oriented programmers with no experience of functional programming (and I include myself from about five years ago in this statement) simply can’t understand how it is possible to write a program in which it’s impossible to change state.
Read the rest of this entry »
The What? and Why? of functional programming
When I talk to fellow programmers about functional programming it’s often about something specific, but occasionally that person will suddenly turn the conversation around and ask “So what actually is functional programming, anyway?”. I will talk about some specific features of FP but I will also cover something more general, a tagline or soundbite with which I could give people an instant sense of the philosophy behind functional programming and how it differs from object-oriented programming. As we will see, however, you can get a lot of the benefits of functional programming even if you don’t program in a function language.
Literally speaking, functional programming means that the basic units of your application (i.e. the bits that you compose together to make a complete program) are functions (as opposed to Object-Oriented Programming when they are classes). However, when it comes to the philosophies of the two, I think we can be a bit broader than that to contrast the two:
The main goal of a code unit in object-oriented / imperative programming is to perform actions
The main goal of a code unit in functional programming is to compute results
Why is this distinction important? It’s why functional programming values concepts such as immutability and purity (which have a whole host of benefits).
Property-based testing
Unit testing. We all do it. Some of us even practice TDD (although I wish I had a penny for each time I see a company claiming that they practice TDD when what they actually mean is “We write unit tests.”).
Test Driven Design means that your development is actually driven by your tests. It doesn’t mean that you write unit tests (although that is required), it doesn’t mean that you write your tests first (although that is also required), but it means that the desired behaviour is implemented incrementally, one test at a time. This normally means that, for each cycle of this method, a single test is written and then the simplest possible implementation is written that will make that test pass. After each test is added and passes (along with the rest of the test suite covering that particular piece of functionality) the developer is free to refactor the code–after all, up until this point the code has grown quite organically and is likely of poor quality. This repeated process is often referred to as Red-Green-Refactor: first the test is added and fails (the test is “red”), then the implementation is augmented until the test passes (the test “goes green”) and then the dev can refactor to improve code quality.
There are many, many different aspects to writing tests, each of which has a hand in how readable, maintainable, comprehensive, useful and correct your test suite is. These include (but are far from limited to): black-box / gray-box / white-box philosophy, mocking strategies, outside-in or inside-out…
But one aspect I don’t hear many people talking about (outside of the functional programming community at least) is how you pick your test cases. It might not seem that important–just throw some example data at the test and assert that for each of those inputs the expected output is produced. Simple, right?
A ha, dear reader. Allow me to throw a spanner in the works.
This doesn’t always work (at least, not well). Let’s go for the most basic of examples:
How would you unit test the + operator?
Examples? 1 + 0? 2 + 2? 423798 + 278? Where do you stop? How would a developer, following TDD by the book, incrementally implement that function?
When designing tests it’s often helpful to pretend that the person writing the tests and the person completing the implementation of the function are different people. Let us play the part of the coder who has been tasked with implementing the “add” function as above. The signature of the function is agreed and the tester throws their first test case at us: 0 + 0. So, we dutifully write the most simple case that will solve that:
let add x y = 0
The test passes. Yay! Now, here comes the second test case: 1, 0 which should equal 1. So:
let add x y =
if x = 1 then 1 else 0
Okay, that’s fine. It’s early days yet! So. 2, 2 = 4?
let add x y =
if x = 1 then 1
elif x = 2 then 4
else 0
Hmmm, it doesn’t look like we’re being driven towards a real implementation here. Maybe let’s try one more test case?
let add x y =
if x = 1 then 1
elif x = 2 then 4
elif x = 423798 && y = 278 then 424076
else 0
No, this isn’t working. We’re solving each case as they come in, but we’re not getting anywhere: the if/else statement is just going to grow and grow and grow. We’re stuck in a loop of: tester adds an example, implementation solves that one particular example.
So, how do you choose your test examples? Wouldn’t it be better if you could randomly generate inputs to your test? It would certainly stop the implementation from devolving into a series of hard-coded values, but then what would you assert? This is something that has fascinated me for a while now.
Allow me to introduce Property-Based Testing.
In this context the word property is used in the mathematical way; a property means some quality, attribute, feature or characteristic that a function, or its input and output, has. In short, property-based testing doesn’t assert what the output is, it instead asserts the the output has some property / characteristic. Sometimes the property you are checking is dependent on the input having some property as well (this may or may not be the same property as you expect to see in the output). An example of this might be:
For any two positive numbers x and y, x + y must be positive
You can see here that we are now able to write an assertion that is true for all inputs to the program. For this particular property–that the output of the function is positive–we have placed a constraint on the input (x and y must be positive). We are now able to automatically generate the input data for our tests because we don’t need to know what the data is in advance.
To see how this might work, let’s write the above property in a more formal language:
For all x, y
where x > 0
and y > 0
it follows that: x + y > 0
It almost looks as if we are now following a Gherkin-style BDD syntax for our tests! Okay, so now we understand what a property is we need to come up with a way of discovering more properties.
Continuing with the mathematical example of addition, your function might have the concept of *identity*. From https://en.wikipedia.org/wiki/Function_(mathematics)#Identity_function, “The unique function over a set X that maps each element to itself is called the identity function for X”, meaning “a function who’s output is always equal to its input”. For addition this is simply “+ 0”, and is a property that we can check.
For all x
it follows that x + 0 = x
There are more mathematical properties that would be useful to check, such as commutativity:
For all x, y:
it follows that x + y = y + x
Associativity:
For all x, y, z
it follows that (x + y) + z = x + (y + z)
Given these properties, it’s now much harder to write an implementation of (+) that is incorrect yet passes all our tests.
This is all very good in theory, but how does this actually work? How do we actually implement this? In part 2 of this series we’ll go through a worked example with something a bit harder than addition: the Diamond Kata.
Code comments
I read a blog post by Jeff Atwood some time ago (warning: this is an old post: https://blog.codinghorror.com/coding-without-comments/) that got me thinking about code comments again. I forget how I came across the blog post but it made me realise that I never, ever comment.
I used to think that comments were an essential part of software development because that’s what I was taught at university and, if I’m honest, they’re still a good idea for junior developers. I have found, though, that in most codebases comments are merely an excuse for poorly-written code. In fact, I would almost go so far as to say that the definition of well-written code is code that needs no comments.
I’d like to clear one thing up before we really begin: I’m talking about comments, not documentation. XML or JavaDoc comments for intellisense are fantastic–if done correctly–for documenting the public surface of your API. From now on when I use the word ‘comment’ I’m talking about double-slashed comments (// such as this) in the middle of a piece of code.
When do we see comments?
Does null equal null?
There are few subjects in programming that are contentious enough to cause heated discussions whenever they come up in conversations, blog posts or Stack Overflow answers. The canonical example of one of these subjects is ‘tabs vs spaces’, but I’ve found another one. It’s something that you may not have thought about before (except occasionally when crafting a SQL query), so let me introduce today’s topic: Does null equal null?
Why records must be sealed
When most people (and I include myself in this) start to learn a functional programming language like F#, they are immediately surprised by the lack of inheritance. It’s such a mainstay of our daily programming that we’re initially nonplussed when it’s taken away… In this post I want to talk about the problems introduced by mixing inheritance with the notion of structural equality, and thus why any language which implements the concept of a record type must also prohibit inheritance of such a type.
For the record (ahem), a record is a type where one simply declares the shape of the class (i.e. the names and types of the public members), and then the constructor, equality and hashcode methods are generated for you by the compiler. An example in F# might be this:
type PersonName = { firstName : string; surname : string }
which is roughly equivalent to the following C#:
Roslyn analyzers
I’ve finally decided to get in on that sweet, sweet Roslyn action and write myself an analyzer (please forgive the American spelling–since I’m programming against a series of types defined in American I’ve decided to use their spelling).
You’ll probably know I’m a big fan of functional programming and I’m trying to write my C# in a more functional style; I’ve found that you can get many of the benefits of functional programming even though you’re not writing in a functional language.
As it turns out, sometimes removing certain features from your programming language (or, at least, disallowing certain actions) can actually improve your code. An easy example of this is the goto statement; despite the fact that the C# language supports goto nobody uses it because it’s widely regarded as a harmful thing to do.
Some functional types in C#
Update: I now have a project on GitHub containing this code at https://github.com/Richiban/Richiban.Func Check this repository for up to date code.
Continuing with my long-running train of thought in bringing some functional programming concepts to my C# projects, I have implemented a type called Optional, roughly equivalent to `Option` from F# or `Maybe a` from Haskell. If you’re not familiar with these concepts, then imagine Nullable from .NET, but applicable to all types (not just value types). The whole idea is that, rather than using a null reference of T to represent a missing value you use a new type–Optional–that can exist in one of two states: it either contains a value of T or does not.
This is a very important difference that I will explain over the course of this post. First, let’s look at the type definition itself. It’s quite long, so feel free to skim-read it at this point and refer back to it at later points in the post.
