The performance characteristics of immutability
If someone asks “What’s the difference between functional and imperative programming?” it’s tempting to reach for the technical definition which is that “a functional program is composed of functions whereas an object-oriented program is composed of classes”. However, a more fundamental difference between functional languages and their cousins in the object-oriented and procedural spaces is the extensive use of immutability.
The reason I consider this to be a more fundamental difference is because object-oriented programmers with no experience of functional programming (and I include myself from about five years ago in this statement) simply can’t understand how it is possible to write a program in which it’s impossible to change state.
Note that I am making a distinction between state and data. Both refer to the storage of information in computer memory, but the term state carries with it the additional connotation that it is something that can be modified or mutated (we talk about the current “state” of an object or the system). Thus, I will reserve use of the term state for referring specifically about mutable information, and data for everything else.
In my last post (The What? and Why? of functional programming) I ended with a little section about the benefits of immutable data structures, such as thread-safety and referential transparency (the idea that any function call can be replaced with its result at every callsite and, therefore, all functions can be cached or memoized). What I would like to talk about today is more to do with the mechanics of immutable data structures as well as their usage patterns and performance characteristics.
Before we begin we must also talk briefly about the difference between mutable references–i.e. a variable in a program that can be made to point at another location in memory–and mutable data structures such as a list whose contents can be modified. (Curiously enough Swift completely conflates these two concepts.)
When we refer to immutability in a functional program we generally mean both these things. It’s important to make the distinction because some languages support one but not the other; an example is C#: it allows us to write immutable objects (i.e. all fields are readonly) but has no concept of a local variable that cannot be reassigned.
I hope to show in this post that, despite our intuition, immutable data is not always less performant that its mutable counterparts. In fact, sometimes it’s quicker! I’d say that it almost ends up being a draw being the two paradigms, depending on the exact task you’re carrying out.
The first–and most obvious–question one might ask is: “But, if your data structures are immutable, surely performance is horrible? Every time you need to make a change to any data you need to make a copy!”.
The answer to this can be found in persistent data structures. A persistent data structure is one in which the old version of the data structure is retained when it is “modified”, in addition to the new version. I’m sure many readers will be astute enough to notice the quotes around the word “modified”. That is because the data structure is not actually modified; instead the operation returns a new instance of the data structure that contains both the new information and a link to the old instance. This is the essence of persistent data structures: since the structure cannot be modified it is always safe to hold a reference to an instance of that data structure, something that would not be safe if the data structure was mutable.
I would like to use an example in C# to illustrate the point. Perhaps the simplest and easiest to understand persistent data structure is the humble singly-linked list. The following contains a very simple, stripped-out implementation:
public class LinkedList<T>
{
private LinkedList() {}
public LinkedList(T head, LinkedList<T> tail)
{
Head = head;
Tail = tail;
HasValue = true;
}
public bool HasValue { get; }
public T Head { get; }
public LinkedList<T> Tail { get; }
public static LinkedList<T> Empty { get; } = new LinkedList<T>();
}
Use like this (please excuse the verbosity; this is C#, after all):
var myList =
new LinkedList<string>("one",
new LinkedList<string>("two",
new LinkedList<string>("three",
LinkedList<string>.Empty));
You can see that the data structure defined above is completely immutable: all properties are read-only and cannot change once the class has been instantiated. Notice how the data structure is also recursive: it is a class called `LinkedList` that contains a reference to another `LinkedList`.
Notice how the way we construct a list is by chaining together lists. In fact, we can think of each of these instances as a node, since each instance consists merely of a single item of data and then a link to the next node. The only way to end this chain is to make use of the singleton `LinkedList.Empty` as you can see.
Let us rewrite the above example (the list “one”, “two”, “three”) simply by introducing some variables:
var endNode = LinkedList<string>.Empty;
var lastNode = new LinkedList<string>("three", endNode);
var middleNode = new LinkedList<string>("two", lastNode);
var firstNode = new LinkedList<string>("one", middleNode);
You’ll agree that what I’ve done here is not complicated (all I’ve done is introduce some variables), but we can now see that you can construct a new list simply by creating a new node and then pointing it at an existing list! This is an important revelation. After all, in the example above, by constructing the node `middleNode` we have given it a reference to `lastNode`, but we haven’t modified `lastNode` at all. We couldn’t have; it’s immutable.
Let’s go back to the above example, but this time I will call the list `a`:
var a =
new LinkedList<string>("one",
new LinkedList<string>("two",
new LinkedList<string>("three",
LinkedList<string>.Empty));
The data structure we call ‘a’ looks a bit like this, in memory:
![]()
You can see that we have a variable named a and the three nodes in memory, each pointing to the next.
Now let’s introduce a new variable b with the definition:
var b = new LinkedList<string>("zero", a);
That leaves us with the following structure in memory:
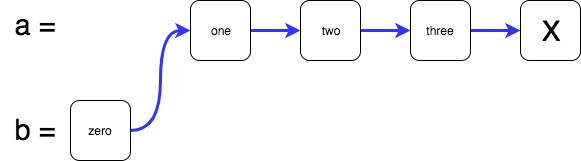
You see we have created a new list b (“zero”, “one”, “two”, “three”) that is a copy of the existing list a (“one”, “two”, “three”) with an extra item added and without mutating anything. That perfectly meets our earlier definition of a persistent data structure in that we have the “new” list b and also the “old” list a. Both exist at the same time and can be used independently.
Note that this is only safe to do if the data structures are immutable; if they weren’t then changes made to one would be reflected in the other too.
Also note that although b can be thought of as “a duplicate of a but with an extra item” note that we haven’t actually done any copying. This was a constant-time operation: O(1).
A recursive data structure, as you might expect from the name, is a natural fit for use with recursion. You can use it to walk a recursive data structure in a very natural way. Let’s see how C#’s IEnumerable works by re-implementing a foreach-loop.
void ForEach<T>(IEnumerable<T> items, Action<T> action)
{
IEnumerator<T> enumerator = items.GetEnumerator();
while(enumerator.MoveNext())
{
action(enumerator.Current);
}
}
You can see that the C# solution is one that makes use of a mutable data structure: IEnumerator. Calling the MoveNext function returns a bool but it also advances the enumerable to next item so that it can retrieved with the Current property.
Let’s see how this might be done in a functional way:
void ForEach<T>(LinkedList<T> list, Action<T> action)
{
if (!list.HasValue) return;
action(list.Head);
ForEach(list.Tail);
}
We’re using recursion instead of looping to go through the list.
If you’re wondering if large collections will eventually blow the stack; they will. Since recursion is such an integral part of programming in functional languages they usually have a compiler optimisation available called tail-call optimisation. This allows the compiler to reuse stack the current stack frame when recursing (given certain conditions are met). When this technique is applied recursion becomes just as efficient as looping.
Fully persistent data structures are not limited to singly-linked lists though. Trees can be represented too:
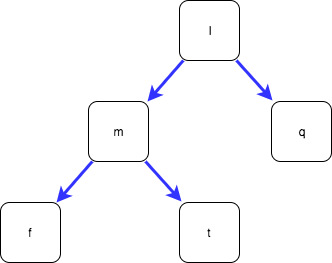
You can see that I can “add” a new node to this tree without modifying the existing tree at all:
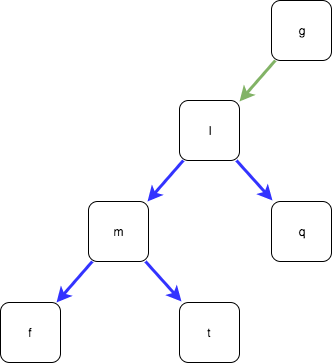
We’re not limited to linking to other “root” nodes, either. Since a tree is also a recursive data structure there’s nothing different about the root node and two trees can share entire subtrees:
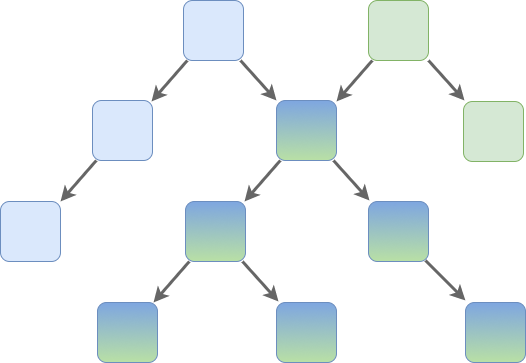
Note again that this data sharing is only safe if the data is immutable.
If it was possible to change the values in these tree nodes then we couldn’t do this.
I’m sure you’ve realised by now that it’s not all rainbows and kittens though. So far we’ve only been swapping out items at the head of our linked list or the root of our tree. What if we have a linked list and we want to, say, replace the 3rd item? Well, in that case we do have to copy some items:
That’s why there isn’t one data structure to rule them all; different structures have different characteristics, advantages and disadvantages. Sometimes it’s important to understand the time and space complexity of the structures and algorithms you’re using (and sometimes it’s just interesting!).
I fully recommend reading up a little more on persistent data structures; it’s a fascinating topic and one that definitely gets deeper as you progress.
