The What? and Why? of functional programming
When I talk to fellow programmers about functional programming it’s often about something specific, but occasionally that person will suddenly turn the conversation around and ask “So what actually is functional programming, anyway?”. I will talk about some specific features of FP but I will also cover something more general, a tagline or soundbite with which I could give people an instant sense of the philosophy behind functional programming and how it differs from object-oriented programming. As we will see, however, you can get a lot of the benefits of functional programming even if you don’t program in a function language.
Literally speaking, functional programming means that the basic units of your application (i.e. the bits that you compose together to make a complete program) are functions (as opposed to Object-Oriented Programming when they are classes). However, when it comes to the philosophies of the two, I think we can be a bit broader than that to contrast the two:
The main goal of a code unit in object-oriented / imperative programming is to perform actions
The main goal of a code unit in functional programming is to compute results
Why is this distinction important? It’s why functional programming values concepts such as immutability and purity (which have a whole host of benefits).
A pure function is one which can have no side effects (the only way for information to leave the function is in its return value) and will always produce the same result if given the same input. For example: a function that adds two numbers together is pure; it doesn’t depend on any external state–only its input values–and it doesn’t write any data anywhere or cause any changes to the state of the system. A function that returns the current date/time, on the other hand, is impure; it takes no arguments but returns a different answer each time it is run because it depends on some changing state of the system.
Not only are pure functions easier for a reader to understand (the signature of the function tells you everything you need to know about what it does) but there are some unexpected performance benefits. In any programming language if two coroutines are ‘pure’ (i.e. they have no side effects) then they are guaranteed to be safe to run in any order, or even in parallel. In fact, all pure algorithms are inherently parallelisable due to this property. There’s no concept of ‘thread safety’ in a pure program: without mutation all functions are automatically thread-safe. This same property allows for lazy evaluation (which Haskell employs), although the value of this is debated.
In addition, pure functions can always be memoized (for OO programmers this basically means ‘indefinitely cached’). Since all a function can ever do is return data, any function call can be replaced by a lookup of its return value.
You might not even need a garbage collector. In a pure language that uses strict evaluation (as opposed to lazy), any objects living on the heap can be removed from memory as soon as they fall out of scope. This is not safe to do in a non-pure language because (due to the ability to call non-pure functions and mutate global state) it is possible for object references to live past the termination of the function that created them.
Eliminating side effects […] can make it much easier to understand and predict the behavior of a program, which is one of the key motivations for the development of functional programming
Basically, this means that it’s much harder to write spaghetti code since functions cannot write outside themselves. The call stack and data flow diagrams map perfectly onto one another.
To help illustrate my point let’s have a look at a flow diagram representing a program:
![]()
If we superimpose the flow of data through our system on top of this diagram, we can see that the two nicely map onto one another and the logic is easy to follow. This is because data can only flow up and down our ‘call stack’ through function arguments and return values:
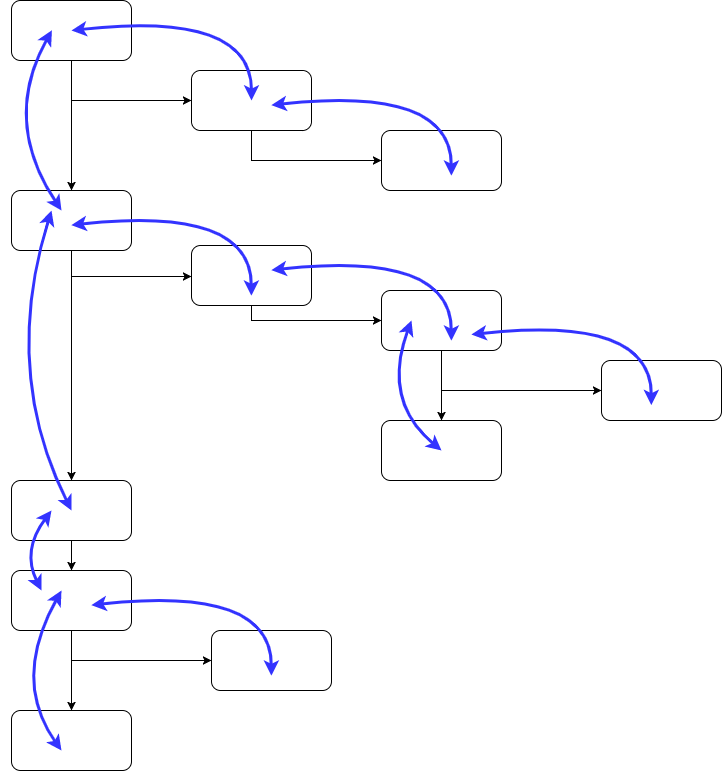
If we try to do the same with an impure program, however, where data can be written to and read from anywhere, things don’t turn out so well at all.
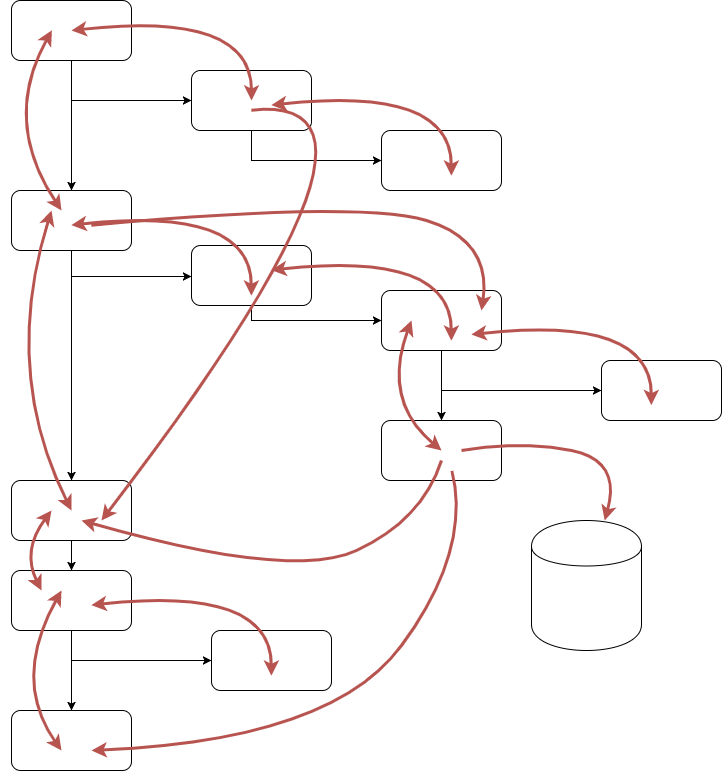
Not only is this now much harder to understand but we also have temporal coupling, that is, procedures that look unrelated to one other need to be run in the correct order because of what they are doing behind the scenes.
Just in case you were worried that this is all getting a little academic, there are more benefits to purity from a software engineering perspective:
- Unit testing is much easier and clearer, since you never have to set up anything other than a function’s arguments and never assert anything other than its return value
- Debugging is easier since bugs cannot be intermittent; they never depend on anything that happened earlier in the system before or will happen after. A function’s return value is either correct for the given inputs or it’s not; it never varies and there are no side-effects to worry about.
Now that I’ve explained some of the benefits of functional programming I hope that you have also noticed along the way that none of this is actually specific to functional languages; it’s just that they either encourage or enforce this behaviour but there’s nothing to stop you from doing it in any other language. In fact, that’s exactly how I write my C# every day and I feel that I’m reaping the rewards! You can too, just give it a try and see what benefits you see and what challenges you come up against if you force yourself to write pure code with immutable objects!
Sidebar: The benefits of immutability
Although immutability doesn’t sound like it should be at all related to functional programming it does dovetail nicely with the concept of purity which is definitely a functional concept. After all, if everything is immutable then you’re halfway there to functional purity (or all the way there if you consider writing to the console or sending a web request to be ‘mutation’).
Having said that, there’s no reason that an imperitive or OO language can’t get some of these benefits at all. After all, with correctly applied access modifiers and use of the readonly keyword a class in C# can be made immutable. But why would we do this? What are the benefits?
- All data is thread-safe. If there’s no mutation of existing data then we have no need for locks, mutexes or syn checks.
- There’s no need to make defensive copies. It’s always safe to pass a piece of data into another function because you know that it can’t be modified.
- Data can be shared which leads to performance benefits. Do understand this we need to talk about persistent data structures (see below)
- Any calculations only need to be performed once. For example: calculating the average value in a list or whether or not a User object is valid. If the underlying data cannot change then these results also cannot change and do not need to be recalculated at another time.
Next time I would like to talk a little more about how immutable data structures can actually be more performant in certain circumstances, through a concept called persistent data structures.

2017-10-23 at 21:36
[…] my last post (The What? and Why? of functional programming) I ended with a little section about the benefits of immutable data structures, such as […]
2018-02-07 at 18:18
excellent post, I also recommend watching https://www.infoq.com/presentations/Are-We-There-Yet-Rich-Hickey